#python program to add two numbers
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Note
I don't know how much you know about coding, so here's some context for an Error headcanon:
If you don't specify that something you input is an integer, then the program (Python at least) won't recognize it as that, and will instead treat it as... well, not a number. For example, if you don't specify that "1" is an integer when you input it and try getting the program to do "1 + 1", then it will give you "11" and not "2" because it just added/smooshed together the two 1s.
Ok now it's headcanon time.
If you asked a question in the right way, then you'd be able to mess with Error a bit. If you asked, "Imagine you have an apple, now add 1. What do you have?"
He wouldn't say "2 apples" like a NORMAL PERSON, nonono, he would reply "1 apple" because in his head and with that phrasing "apple + 1 = apple1". He's just rearranging the sentence structure because he figures that that's probably the answer you're looking for
I’M. EXPLODING YOU WITH MY MIND RIGHT NOW/POS. AAAHRGEJAJHFJRHGJR
YESYES I DO KNOW A BIT OF CODE AND YES THIS MAKES SM SENSE I HAVE NO IDEA WHY I NEVER THOUGHT ABT THIS I AM SOOOOO YOINKING THIS AAAHDWHGFJEHWIFHWJHFHGHG
IM SORRY I TOOK SO LONG TO REPLY BUT I JST LOVED THIS SM I HAD TO DOODLE SMTH ABT IT

#IM GOING TO. STEAL YOUR BRAIN.#WHAT THE FUCK#HOW DO U HAVE SO MANY FIRE HCS IM GONNA CRASH OUT#AAEHGFJWUDKDHFHHFHFJE#anyway tags time heh#yay an ask!!!!#error sans#ink sans#utmv#sans au
73 notes
·
View notes
Text
Why Not Write Cryptography
I learned Python in high school in 2003. This was unusual at the time. We were part of a pilot project, testing new teaching materials. The official syllabus still expected us to use PASCAL. In order to satisfy the requirements, we had to learn PASCAL too, after Python. I don't know if PASCAL is still standard.
Some of the early Python programming lessons focused on cryptography. We didn't really learn anything about cryptography itself then, it was all just toy problems to demonstrate basic programming concepts like loops and recursion. Beginners can easily implement some old, outdated ciphers like Caesar, Vigenère, arbitrary 26-letter substitutions, transpositions, and so on.
The Vigenère cipher will be important. It goes like this: First, in order to work with letters, we assign numbers from 0 to 25 to the 26 letters of the alphabet, so A is 0, B is 1, C is 2 and so on. In the programs we wrote, we had to strip out all punctuation and spaces, write everything in uppercase and use the standard transliteration rules for Ä, Ö, Ü, and ß. That's just the encoding part. Now comes the encryption part. For every letter in the plain text, we add the next letter from the key, modulo 26, round robin style. The key is repeated after we get tot he end. Encrypting "HELLOWORLD" with the key "ABC" yields ["H"+"A", "E"+"B", "L"+"C", "L"+"A", "O"+"B", "W"+"C", "O"+"A", "R"+"B", "L"+"C", "D"+"A"], or "HFNLPYOLND". If this short example didn't click for you, you can look it up on Wikipedia and blame me for explaining it badly.
Then our teacher left in the middle of the school year, and a different one took over. He was unfamiliar with encryption algorithms. He took us through some of the exercises about breaking the Caesar cipher with statistics. Then he proclaimed, based on some back-of-the-envelope calculations, that a Vigenère cipher with a long enough key, with the length unknown to the attacker, is "basically uncrackable". You can't brute-force a 20-letter key, and there are no significant statistical patterns.
I told him this wasn't true. If you re-use a Vigenère key, it's like re-using a one time pad key. At the time I just had read the first chapters of Bruce Schneier's "Applied Cryptography", and some pop history books about cold war spy stuff. I knew about the problem with re-using a one-time pad. A one time pad is the same as if your Vigenère key is as long as the message, so there is no way to make any inferences from one letter of the encrypted message to another letter of the plain text. This is mathematically proven to be completely uncrackable, as long as you use the key only one time, hence the name. Re-use of one-time pads actually happened during the cold war. Spy agencies communicated through number stations and one-time pads, but at some point, the Soviets either killed some of their cryptographers in a purge, or they messed up their book-keeping, and they re-used some of their keys. The Americans could decrypt the messages.
Here is how: If you have message $A$ and message $B$, and you re-use the key $K$, then an attacker can take the encrypted messages $A+K$ and $B+K$, and subtract them. That creates $(A+K) - (B+K) = A - B + K - K = A - B$. If you re-use a one-time pad, the attacker can just filter the key out and calculate the difference between two plaintexts.
My teacher didn't know that. He had done a quick back-of-the-envelope calculation about the time it would take to brute-force a 20 letter key, and the likelihood of accidentally arriving at something that would resemble the distribution of letters in the German language. In his mind, a 20 letter key or longer was impossible to crack. At the time, I wouldn't have known how to calculate that probability.
When I challenged his assertion that it would be "uncrackable", he created two messages that were written in German, and pasted them into the program we had been using in class, with a randomly generated key of undisclosed length. He gave me the encrypted output.
Instead of brute-forcing keys, I decided to apply what I knew about re-using one time pads. I wrote a program that takes some of the most common German words, and added them to sections of $(A-B)$. If a word was equal to a section of $B$, then this would generate a section of $A$. Then I used a large spellchecking dictionary to see if the section of $A$ generated by guessing a section of $B$ contained any valid German words. If yes, it would print the guessed word in $B$, the section of $A$, and the corresponding section of the key. There was only a little bit of key material that was common to multiple results, but that was enough to establish how long they key was. From there, I modified my program so that I could interactively try to guess words and it would decrypt the rest of the text based on my guess. The messages were two articles from the local newspaper.
When I showed the decrypted messages to my teacher the next week, got annoyed, and accused me of cheating. Had I installed a keylogger on his machine? Had I rigged his encryption program to leak key material? Had I exploited the old Python random number generator that isn't really random enough for cryptography (but good enough for games and simulations)?
Then I explained my approach. My teacher insisted that this solution didn't count, because it relied on guessing words. It would never have worked on random numeric data. I was just lucky that the messages were written in a language I speak. I could have cheated by using a search engine to find the newspaper articles on the web.
Now the lesson you should take away from this is not that I am smart and teachers are sore losers.
Lesson one: Everybody can build an encryption scheme or security system that he himself can't defeat. That doesn't mean others can't defeat it. You can also create an secret alphabet to protect your teenage diary from your kid sister. It's not practical to use that as an encryption scheme for banking. Something that works for your diary will in all likelihood be inappropriate for online banking, never mind state secrets. You never know if a teenage diary won't be stolen by a determined thief who thinks it holds the secret to a Bitcoin wallet passphrase, or if someone is re-using his banking password in your online game.
Lesson two: When you build a security system, you often accidentally design around an "intended attack". If you build a lock to be especially pick-proof, a burglar can still kick in the door, or break a window. Or maybe a new variation of the old "slide a piece of paper under the door and push the key through" trick works. Non-security experts are especially susceptible to this. Experts in one domain are often blind to attacks/exploits that make use of a different domain. It's like the physicist who saw a magic show and thought it must be powerful magnets at work, when it was actually invisible ropes.
Lesson three: Sometimes a real world problem is a great toy problem, but the easy and didactic toy solution is a really bad real world solution. Encryption was a fun way to teach programming, not a good way to teach encryption. There are many problems like that, like 3D rendering, Chess AI, and neural networks, where the real-world solution is not just more sophisticated than the toy solution, but a completely different architecture with completely different data structures. My own interactive codebreaking program did not work like modern approaches works either.
Lesson four: Don't roll your own cryptography. Don't even implement a known encryption algorithm. Use a cryptography library. Chances are you are not Bruce Schneier or Dan J Bernstein. It's harder than you thought. Unless you are doing a toy programming project to teach programming, it's not a good idea. If you don't take this advice to heart, a teenager with something to prove, somebody much less knowledgeable but with more time on his hands, might cause you trouble.
358 notes
·
View notes
Text
Slow and Pause
Part of my solving of the issues with my sudoku solver couldn't have happened without diagnosing the problem. And that couldn't happen until I could see what the program was DOING.
Thing is, when your program does millions of things in order to get to its answer, and a terminal can only keep the last few hundred lines, you can have a hard time getting accurate info about what happened in the middle.
The two things I learned to help with that:
Pressing ctrl-z with the terminal selected will pause the program in operation. You can type "fg" and hit enter to resume the last paused program.
For Python, you can also use the sleep() function, from the Time class. So up top you add
import time
and then wherever the loop is happening that you want to see the middle of, you can add, say,
time.sleep(0.1)
This will keep looping at a pretty high clip - once every 1/10 of a second - but slow enough that you can possibly catch what's happening and press ctrl-z to pause and take a closer look. Depending on your reflexes and the length of the loop in question (or if you suspect the problem is right at the start of the looping), you can set the duration in there to whatever number of seconds works for you.
10 notes
·
View notes
Text
Strange way of drawing the Dragon Curve

Alright, so real quick I just want to share potentially the most arcane method of drawing the Dragon Curve I've ever seen, derived and designed by yours truly! As far as I know, this is a novel solution. I know the sequence it generates is known, but I'm not sure if anyone else has used this method before. Its quite elegant if I may say so myself.

So for those that aren't aware in programming the "<<" and ">>" operators are sometimes known as "bit shifts." Basically what this is doing is starting at some number, adding a power of two, then getting a specific 1 or 0 in the binary representation of that number iteratively, until its searched enough bits to know they aren't going to change anymore.
It has to do with this sequence right here. I've mentioned before, my personal favorite way of generating the dragon curve is to start with the sequence 0, reverse it, add one, roll over once you reach 4, and tack that on to the original sequence. So 0 0 1 0 1 2 1 0 1 2 1 2 3 2 1 0 1 2 1 2 3 2 1 2 3 0 3 2 3 2 1 Well what ends up happening is each time you add one, its like adding one to the reversed part of the newly added sequence. So we can track where all these 1's come from based on when they're added. For example, the 1 we added in the "01" step turns into 0 1 0 1 1 0 0 1 1 0 0 1 1 0 Note from here on out its palindromic, so reversing it no longer has any effect. What we end up with is a repeating pattern of two 1's, then two 0's, starting with half that many 0's. When going from 0 1 0 1 2 1 We're adding 1's to the entire second half, so in this step the 1's propagate to 0 0 1 1 0 0 1 1 1 1 0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 0 0 And again, this is now palindromic. Four 1's, four 0's led by half that many. One of the things I've learned about the dragon curve is just how intrinsically linked it is to binary (and this makes sense when you think of the folding paper method of generating it. Here's an excel spreadsheet demonstrating this in action
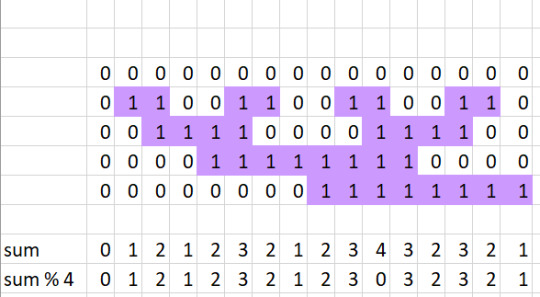
Now here's the fun part. My research was to parallelize this algorithm. One approach is to say "Okay, how can we calculate each term in this sequence without looking at the previous ones." And the answer is to exploit these very predictable patterns. And how do we predict these patterns? Simple, we simply count in binary
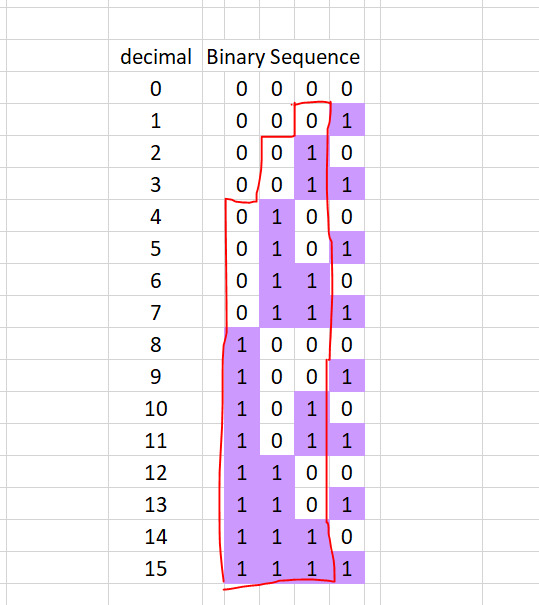
The right most column is useless, but starting at the next one to the left, we see a familiar pattern, almost. Say we want to know what the 5th number in the dragon curve sequence is (0 indexed). To make the sequence only lead with one 0 instead of two, we need to offset by 1, then all we have to do is increase the number by (n + 1) = 5 and take its 2nd least significant bit (1 indexed because english). The 2nd bit of ( 1 + 5 = 6 ) is a 1. For the next iteration we're looking at the 3rd least significant bit. Here we need to offset by 2, and then we increase the number by 5 again and the 3rd significant bit is the one we take. The 3rd bit of (2 + 5 = 7) is another 1 After that we're looking at the 4th least significant bit. We need to offset by 4, then increase the number by 5, and the 4th significant bit will give us our number. The 4th bit of (4 + 5 = 9) is going to be another 1, bringing our total to 3. Here's a visual representation
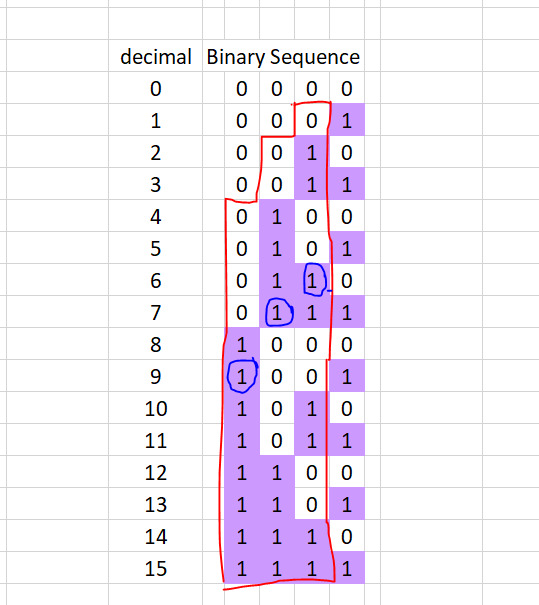
This is where the "1 << i" comes in, because that's the same as saying 2^i, which is how we get those offsets of 1, 2, 4, then 8, 16, 32... the "n" in "n + (1 << i)" comes from us offsetting to get the nth term in each sequence Finally the " >> (i + 1) " and "% 2" are to fetch the (i + 1)th bit from the number. After that the increasing size of the leading zero's outpaces our constant offset of the number 5, so we are only going to get 0's from here on out, and we can actually stop, hence the usage of bit length to terminate the loop early.
And if we look at the the 5th element of the sequence (0 indexed) 0 1 2 1 2 3 Funnily enough, in python this brings an actual speed increase (or at least, distributes the cost over the drawing) because of how slow reading and writing to memory is, compared to how math and bit-wise operations are implemented in low level C behind the scenes. Additionally, since there is no reliance on previous work this task can be multi-threaded, or even GPU accelerated if need be. Finally, if you've made it this far, here are a few images of some close ups of dragon curves from my GPU implemented (unrelated to this one entirely) just so that there's something pretty. Enjoy <3


#Dragon curve#fractal#programming#progblr#codeblr#python#fractals#math#computer science#algorithms#binary
126 notes
·
View notes
Text
I am remembering things about this generator. First off:
FinalRelationshipValue="{} {} (a {} {} {}), {} (a {} {}) and {} (a {}). One time, {} {} {}, who {} it. "
I'm remembering how silly strings look without their added data in them. Like, yep, that sure is a statement :) Such a valid sentence.
Also, with the disorders, I forgot that I researched statistics for things like "percentage of people missing an arm" and used that in the generator. Your guy has a 4 in 10,000 chance to be missing an arm, and a 28 in 1000 chance to have ADHD. Where did I get this data from? I don't remember. I googled something and found numbers and called it good enough I guess. Anyways there are only three disorders, those two and "Sleepy Bitch Disorder" Which is :\ well that's not a lot. But! I remember asking a few times for things to add, and no one submitted things, and those were just the three I added in to test the feature out. BTW your dragon could potentially have all disorders at once. It's not very probable but it could happen.
Also I absolutely had bias stuff in some of the results, such as for common pronouns and creatures. I have removed all those biases for v2.0.0 👍
Looking at the Hydra code and 😬 that's a lot. Like, it's not hard to understand, there's just a lot with it. Every time a head is added, it cuts the percentage in 1/2 for the next head, and then the final head count needs personalities for each head. But not every thing is multiplied either. Hydras are in v1.1.0 tho, and I never finished them 😔 In fact v2.0.0 might not include them, we'll see how that goes.
Anyways I've started on cleaning up v1.0.2 so that I can understand things easier for when I make the web version. Until then . ..
It'll still be one every 3 hours, so 8 Dragons a day. All the old copyright rules still apply, anyone can use any creature that spits out. I have a .bat file that'll run the Python program 250 times in about 5 seconds, which'll make 31.25 days, basically lasting us until 2025
Also I'll be setting up a bunch of proper blog tags over the next week or two, and update the pinned content as well. Reviving an abandoned blog is a lot of work :P
7 notes
·
View notes
Text
India’s Tech Sector to Create 1.2 Lakh AI Job Vacancies in Two Years
India’s technology sector is set to experience a hiring boom with job vacancies for artificial intelligence (AI) roles projected to reach 1.2 lakh over the next two years. As the demand for AI latest technology increases across industries, companies are rapidly adopting advanced tools to stay competitive. These new roles will span across tech services, Global Capability Centres (GCCs), pure-play AI and analytics firms, startups, and product companies.
Following a slowdown in tech hiring, the focus is shifting toward the development of AI. Market analysts estimate that Indian companies are moving beyond Proof of Concept (PoC) and deploying large-scale AI systems, generating high demand for roles such as AI researchers, product managers, and data application specialists. “We foresee about 120,000 to 150,000 AI-related job vacancies emerging as Indian IT services ramp up AI applications,” noted Gaurav Vasu, CEO of UnearthInsight.
India currently has 4 lakh AI professionals, but the gap between demand and supply is widening, with job requirements expected to reach 6 lakh soon. By 2026, experts predict the number of AI specialists required will hit 1 million, reflecting the deep integration of AI latest technology into industries like healthcare, e-commerce, and manufacturing.
The transition to AI-driven operations is also altering the nature of job vacancies. Unlike traditional software engineering roles, artificial intelligence positions focus on advanced algorithms, automation, and machine learning. Companies are recruiting experts in fields like deep learning, robotics, and natural language processing to meet the growing demand for innovative AI solutions. The development of AI has led to the rise of specialised roles such as Machine Learning Engineers, Data Scientists, and Prompt Engineers.
Krishna Vij, Vice President of TeamLease Digital, remarked that new AI roles are evolving across industries as AI latest technology becomes an essential tool for product development, operations, and consulting. “We expect close to 120,000 new job vacancies in AI across different sectors like finance, healthcare, and autonomous systems,” he said.
AI professionals also enjoy higher compensation compared to their traditional tech counterparts. Around 80% of AI-related job vacancies offer premium salaries, with packages 40%-80% higher due to the limited pool of trained talent. “The low availability of experienced AI professionals ensures that artificial intelligence roles will command attractive pay for the next 2-3 years,” noted Krishna Gautam, Business Head of Xpheno.
Candidates aiming for AI roles need to master key competencies. Proficiency in programming languages like Python, R, Java, or C++ is essential, along with knowledge of AI latest technology such as large language models (LLMs). Expertise in statistics, machine learning algorithms, and cloud computing platforms adds value to applicants. As companies adopt AI latest technology across domains, candidates with critical thinking and AI adaptability will stay ahead so it is important to learn and stay updated with AI informative blogs & news.
Although companies are prioritising experienced professionals for mid-to-senior roles, entry-level job vacancies are also rising, driven by the increased use of AI in enterprises. Bootcamps, certifications, and academic programs are helping freshers gain the skills required for artificial intelligence roles. As AI development progresses, entry-level roles are expected to expand in the near future. AI is reshaping the industries providing automation & the techniques to save time , to increase work efficiency.
India’s tech sector is entering a transformative phase, with a surge in job vacancies linked to AI latest technology adoption. The next two years will witness fierce competition for AI talent, reshaping hiring trends across industries and unlocking new growth opportunities in artificial intelligence. Both startups and established companies are racing to secure talent, fostering a dynamic landscape where artificial intelligence expertise will be help in innovation and growth. AI will help organizations and businesses to actively participate in new trends.
#aionlinemoney.com
2 notes
·
View notes
Text
Exercise to do with python :

Write a Python program to print "Hello, World!"
This is a basic Python program that uses the print statement to display the text "Hello, World!" on the console.
Write a Python program to find the sum of two numbers.
This program takes two numbers as input from the user, adds them together, and then prints the result.
Write a Python function to check if a number is even or odd.
This exercise requires you to define a function that takes a number as input and returns a message indicating whether it is even or odd.
Write a Python program to convert Celsius to Fahrenheit.
This program prompts the user to enter a temperature in Celsius and then converts it to Fahrenheit using the conversion formula.
Write a Python function to check if a given year is a leap year.
In this exercise, you'll define a function that checks if a year is a leap year or not, based on leap year rules.
Write a Python function to calculate the factorial of a number.
You'll create a function that calculates the factorial of a given non-negative integer using recursion.
Write a Python program to check if a given string is a palindrome.
This program checks whether a given string is the same when read backward and forward, ignoring spaces and capitalization.
Write a Python program to find the largest element in a list.
The program takes a list of numbers as input and finds the largest element in the list.
Write a Python program to calculate the area of a circle.
This program takes the radius of a circle as input and calculates its area using the formula: area = π * radius^2.
Write a Python function to check if a string is an anagram of another string.
This exercise involves writing a function that checks if two given strings are anagrams of each other.
Write a Python program to sort a list of strings in alphabetical order.
The program takes a list of strings as input and sorts it in alphabetical order.
Write a Python function to find the second largest element in a list.
In this exercise, you'll create a function that finds the second largest element in a list of numbers.
Write a Python program to remove duplicate elements from a list.
This program takes a list as input and removes any duplicate elements from it.
Write a Python function to reverse a list.
You'll define a function that takes a list as input and returns the reversed version of the list.
Write a Python program to check if a given number is a prime number.
The program checks if a given positive integer is a prime number (greater than 1 and divisible only by 1 and itself).
Write a Python function to calculate the nth Fibonacci number.
In this exercise, you'll create a function that returns the nth Fibonacci number using recursion.
Write a Python program to find the length of the longest word in a sentence.
The program takes a sentence as input and finds the length of the longest word in it.
Write a Python function to check if a given string is a pangram.
This function checks if a given string contains all the letters of the alphabet at least once.
Write a Python program to find the intersection of two lists.
The program takes two lists as input and finds their intersection, i.e., the common elements between the two lists.
Write a Python function to calculate the power of a number using recursion.
This function calculates the power of a given number with a specified exponent using recursion.
Write a Python program to find the sum of the digits of a given number.
The program takes an integer as input and finds the sum of its digits.
Write a Python function to find the median of a list of numbers.
In this exercise, you'll create a function that finds the median (middle value) of a list of numbers.
Write a Python program to find the factors of a given number.
The program takes a positive integer as input and finds all its factors.
Write a Python function to check if a number is a perfect square.
You'll define a function that checks whether a given number is a perfect square (i.e., the square root is an integer).
Write a Python program to check if a number is a perfect number.
The program checks whether a given number is a perfect number (the sum of its proper divisors equals the number itself).
Write a Python function to count the number of vowels in a given string.
In this exercise, you'll create a function that counts the number of vowels in a given string.
Write a Python program to find the sum of all the multiples of 3 and 5 below 1000.
The program calculates the sum of all multiples of 3 and 5 that are less than 1000.
Write a Python function to calculate the area of a triangle given its base and height.
This function calculates the area of a triangle using the formula: area = 0.5 * base * height.
Write a Python program to check if a given string is a valid palindrome ignoring spaces and punctuation.
The program checks if a given string is a palindrome after removing spaces and punctuation.
Write a Python program to find the common elements between two lists.
The program takes two lists as input and finds the elements that appear in both lists.
15 notes
·
View notes
Text
Some things I will add regarding the Tumblr Utils method:
If you have other python software installed, you might need to remove them lest your computer have an issue with which version of Python to run the script on, I had to remove a C++ emulator which was clashing with the python for some reason, though admittedly that program never actually worked for me.
Use the command window rather than trying to download and run the code yourself, the link in the document points to a version of the code that was incompatible with the current Python version I was using and I wasted close to two hours trying to force it to run before giving up.
The API key request appears to be automatic, so you don't have to wait for one of the few remaining staff members to personally authorize you.
This is the current line of code that works to backup your account:
tumblr-backup --save-audio --save-video --tag-index --incremental blog-name
Replace "blog-name" with your blog name.
save-audio and save-video are self explanatory, however I did encounter some issues with posts where videos couldn't be saved. The program will give you a post number pointing to which post couldn't be saved, so if you wish you can go and save those videos/audios through a different method. tag-index creates an index of every tag you've ever used, which is helpful but also note that it means every tag. incremental is perhaps the most useful one, as it allows you to keep updating the backup. The document uses --i, which according to the script I ran is no longer used.
Good wifi is absolutely recommended as this thing ate up most of my bandwidth and took nearly 3 days for about 91000 posts. Another important command, especially if you have wifi troubles, is
tumblr-backup --save-audio --save-video --tag-index --continue blog-name
If ever your command is interrupted, this allows the program to continue from where the last increment stopped. I made a notepad file containing these two lines and just copied + pasted them any time the program crashed.
You can use your computer while this runs, I set mine up with a power connection and disabled the auto shutdown feature. I do recommend doing this, it's not difficult as long as you don't have the world's most unique computer problems like I did.
Btw much as I love to make fun of twitter and reddit's business decisions, I have 0% trust in tumblr's management to not go a similar route so this is your gentle reminder that you should regularly go to your blog settings to export your blog. That's a fancy way of saying you can download a backup of your blog so if everything goes down you'll still have a backup of your posts & convos.
#tumblr#tumblr backup#it appears to save it all as html so it could in theory be exported to a new blog altogether#my favourite error was 'python does not have python installed'#that turned out to be an issue with the path
120K notes
·
View notes
Text
Python: 100 Simple Codes

Python: 100 Simple Codes
Beginner-friendly collection of easy-to-understand Python examples.

Each code snippet is designed to help you learn programming concepts step by step, from basic syntax to simple projects. Perfect for students, self-learners, and anyone who wants to practice Python in a fun and practical way.
Codes:
1. Print Hello World
2. Add Two Numbers
3. Check Even or Odd
4. Find Maximum of Two Numbers
5. Simple Calculator
6. Swap Two Variables
7. Check Positive, Negative or Zero
8. Factorial Using Loop
9. Fibonacci Sequence
10. Check Prime Number
===
11. Sum of Numbers in a List
12. Find the Largest Number in a List
13. Count Characters in a String
14. Reverse a String
15. Check Palindrome
16. Generate Random Number
17. Simple While Loop
18. Print Multiplication Table
19. Convert Celsius to Fahrenheit
20. Check Leap Year
===
21. Find GCD (Greatest Common Divisor)
22. Find LCM (Least Common Multiple)
23. Check Armstrong Number
24. Calculate Power (Exponent)
25. Find ASCII Value
26. Convert Decimal to Binary
27. Convert Binary to Decimal
28. Find Square Root
29. Simple Function
30. Function with Parameters
===
31. Function with Default Parameter
32. Return Multiple Values from Function
33. List Comprehension
34. Filter Even Numbers from List
35. Simple Dictionary
36. Loop Through Dictionary
37. Check if Key Exists in Dictionary
38. Use Set to Remove Duplicates
39. Sort a List
40. Sort List in Descending Order
===
41. Create a Tuple
42. Loop Through a Tuple
43. Unpack a Tuple
44. Find Length of a List
45. Append to List
46. Remove from List
47. Pop Last Item from List
48. Use range() in Loop
49. Use break in Loop
50. Use continue in Loop
===
51. Check if List is Empty
52. Join List into String
53. Split String into List
54. Use enumerate() in Loop
55. Nested Loop
56. Simple Class Example
57. Class Inheritance
58. Read Input from User
59. Try-Except for Error Handling
60. Raise Custom Error
===
61. Lambda Function
62. Map Function
63. Filter Function
64. Reduce Function
65. Zip Two Lists
66. List to Dictionary
67. Reverse a List
68. Sort List of Tuples by Second Value
69. Flatten Nested List
70. Count Occurrences in List
===
71. Check All Elements with all()
72. Check Any Element with any()
73. Find Index in List
74. Convert List to Set
75. Find Intersection of Sets
76. Find Union of Sets
77. Find Difference of Sets
78. Check Subset
79. Check Superset
80. Loop with Else Clause
===
81. Use pass Statement
82. Use del to Delete Item
83. Check Type of Variable
84. Format String with f-string
85. Simple List Slicing
86. Nested If Statement
87. Global Variable
88. Check if String Contains Substring
89. Count Characters in Dictionary
90. Create 2D List
===
91. Check if List Contains Item
92. Reverse a Number
93. Sum of Digits
94. Check Perfect Number
95. Simple Countdown
96. Print Pattern with Stars
97. Check if String is Digit
98. Check if All Letters Are Uppercase
99. Simple Timer with Sleep
100. Basic File Write and Read
===
0 notes
Text
Code with Confidence: Programming Course in Pitampura for Everyone
What is Programming?
Programming, coding, or software development refers to the activity of typing out instructions (code) that will tell a computer to perform something in order for it to perform some task. These tasks may be as simple as doing arithmetic or may be complex tasks like the functioning of an operating system or even the creation of an AI system. Programming is essentially problem-solving by providing a computer with a specified set of instructions to perform.
In a standard programming process, a programmer codes in a programming language. The computer converts the code into machine language (binary), which the computer understands and executes. Through this, computers are able to perform anything from straightforward computations to executing humongous, distributed systems.

The Process of Programming
1. Writing Code
The initial step in coding is to code. Programmers utilize programming languages to code their commands. The languages differ in their complexity and composition but all work to translate human reasoning to machines.Programming Course in Pitampura
programming languages are Python, JavaScript, Java, C++, and numerous others.
A programmer begins by determining what problem they have to fix and then dissecting it into steps that they can do. For instance, if they have to create a program that will find the area of a rectangle, they may first have to create instructions that will accept the input values (width and length) and then carry out the multiplication to obtain the area.
2. Conversion of Code to Machine Language
After the code is written, the second step is to convert it into something that the computer can read. There are two main methods of doing that:
Compilation: In languages such as C and C++, the source code is compiled in its entirety to machine code by a compiler. This gives an executable file, which will execute independently without the source code.
Interpretation: In interpreted languages like Python, the code is executed line by line by an interpreter. The interpreter translates the code to machine language while executing the program, so the initial source code is always required.
3. Execution
Once the code has been translated into machine language, the computer can execute it. That is, the program does what the programmer instructed it to do, whether it is displaying information on a web page, calculating a result, or talking to a database.
Key Concepts in Programming
1. Variables and Data Types
A variable is a storage container where data is put that may vary while the program is running. Data put in variables may be of various types, and those types are referred to as data types. Data types include:
Integers: Whole numbers (e.g., 5, -10)
Floating-point numbers: Decimal numbers (e.g., 3.14, -0.001)
Strings: Sequences of characters (e.g., "Hello World!")
Booleans: True or false values (e.g., True or False)
2. Control Structures
Control structures help direct the course of a program. They enable a program to make decisions (conditionals) or perform actions in cycles (loops). The two fundamental control structures are:
Conditionals: Applied when programming choices are being made. For instance: if age >= 18:
print("You are an adult.")
else:
print("You are a minor.")
Loops: Loops allow a program to repeat a set of instructions. For example, a for loop might be used to print numbers from 1 to 5: for i in range(1, 6):
print(i)
3. Functions
A function is a section of code that can be repeatedly called to perform a task. Functions avoid duplicated code and make programs modular. Functions will typically have arguments (input), perform something, and return a result. For example:
def add(a, b):
return a + b
result = add(3, 5)
print(result) # Output: 8
4. Object-Oriented Programming (OOP)
OOP is a programming paradigm in which the program is structured around objects—data and the operations that take data as input. An object is an instance of a class, which is like a blueprint for creating objects. The main ideas of OOP are:
Encapsulation: Putting data and functions into one container (class).
Inheritance: Providing a class to inherit properties from another class.
Polymorphism: Enabling the use of several classes as objects of a shared base class.
Example of a class in Python:
class Car:
def __init__(self, brand, model):
self.brand = brand
self.model = model
def start_engine(self):
print(f"Starting the engine of the {self.brand} {self.model}.")
my_car = Car("Toyota", "Corolla")
my_car.start_engine()
Common Programming Paradigms
Procedural Programming:- This is the most basic programming paradigm, where instructions are written as a series of instructions that are carried out one after the other. Similar instructions are bundled with the assistance of functions. It is suitable for straightforward problems.
Object-Oriented Programming (OOP):- As mentioned, OOP deals with objects and classes. It is especially beneficial in large programs where maintainability and reusability of code are major issues. OOP is supported by programming languages such as Java, Python, and C++. It.
Functional Programming:- This paradigm considers computation as the calculation of mathematical functions and does not change state or mutable data. Haskell and Scala are both popular for their focus on functional programming.
Declarative Programming:- In declarative programming, you define what you wish to accomplish rather than how you wish to accomplish it. SQL (Structured Query Language) is a case in point, where you tell the database what information you want to pull rather than how to pull it.
Common Programming Languages
Python: Known for simplicity and readability, Python is used extensively in web development, data science, AI, etc. It is an interpreted language, meaning you can begin coding without the hassles of compilation.
JavaScript: The most significant programming language for web development. JavaScript is run in the browser and used to create interactive and dynamic web pages. JavaScript can also be used on the server side in environments like Node.js.
Java: A compiled language with wide application to enterprise software, Android apps, and large systems. It is renowned for being solid and cross-platform (via the Java Virtual Machine).
C/C++: C is a very mature and robust programming language, used in systems programming and embedded systems. C++ adds object-oriented programming features to C and is generally used for high-performance applications, such as video games.
Ruby: Ruby, with its beautiful syntax, is widely utilized for web development using the Ruby on Rails framework.
Debugging and Testing
Programming has many different aspects, and coding is just one of them. Debugging is finding and fixing bugs in your code, and testing is verifying your code to run the way you want it to. There are unit tests, integration tests, and debuggers among some of the tools that assist you in getting your programs' quality and correctness.
Real-World Applications of Programming
Programming powers an enormous range of programs in daily life:
Web Development: Creating a web site and web applications using technologies like HTML, CSS, JavaScript, and frameworks like React or Angular.
Mobile Application Development: Developing apps for iOS (Swift) or Android (Java/Kotlin).
Data Science: Examining data using programs such as Python, R, and SQL, generally to discover trends and insights.
Game Development: Creating video games with programming languages like C++ and game engines like Unity or Unreal Engine.
Artificial Intelligence: Developing intelligent systems with learning and decision-making capabilities, using Python and libraries like TensorFlow or PyTorch.
Conclusion
Programming is a multi-purpose and valuable skill in the modern world. It allows us to code and break down complex issues, perform tasks automatically, and design anything from a simple calculator to a sophisticated artificial intelligence system. Whether you want to design websites, inspect data, or design mobile applications, programming is the core of contemporary technology. The more you learn and experiment, the more you will realize the incredible possibilities of what you can construct and accomplish.
1 note
·
View note
Text
OSRR: 3861
this is a number that is divisible by 3. and by 9. and by 27.
if you add up the digits of a number and you get a number that's divisible by 3, it's divisible by three. if you can do that twice, it's divisible by 9. if it can do it three times, it's divisible by 27. and it keeps going.
anyway.
today was quiet.
i woke up a few times last night, kind of upset about the fact that i kept waking up, but when i woke up around 7, i was okay with it. because it was light out, mostly, but it was gray. so i could go back to sleep. and then i woke up around 8:30, and stayed in bed a bit, got up maybe a little after 9? showered, got dressed, etc. i dressed in something lighter today, because it was gonna be warmer (in the 50s) so i paired some jeans with a light gauzy shirt with flowers on it. put it with a camel-colored sweater and my black sneakers and had myself a very nice outfit. it made me happy to be wearing springtime colors, which was intentional because it was VERY gray all day.
i went grocery shopping with mom again today, and she was having a rough time walking around.
something that happens every time i go shopping with mom and she's on the phone, i run to get something really quickly, and i expect she'll stay where she is and keep talking on the phone. but she ALWAYS disappears. so i told her "if you are on the phone and i leave you somewhere to get something, STAY WHERE YOU ARE." there have been TOO MANY TIMES where i have angrily walked up and down the store with heavy things in my arms because i expected to be able to plop it right in the cart. this time when she disappeared, i stayed where i was since i was in the front of the store in the middle and was easily visible. and it was so much easier on me to just stay there. i didn't get angry and it was such a difference. it was so silly.
mom did get dizzy a couple of times while we were there, which was unsurprising, but i worry for her.
we stopped and got lunch after and sat and watched a lady feed de bords some bread. we had to go home quickly because we had ice cream.
after bringing everything in and putting it away, mom and i folded some laundry and talked to my oldest brother on the phone for a little bit. and then i went and took a nap. my problem, though, with taking a nap was messing up my hair, which looked really nice and was the appropriate level of everything. didn't wanna mess that up. so i laid down and put my feet out and stayed on my back and just. i slept without moving. and it was such a nice nap. i slept about two hours or so before my body decided to wake up before my alarm. i heard movement and then my mom and sister were talking in the other room which i could hear a little but of over the fan. so i woke up.
and then i headed out for class.
the material made sense. i got to be the math guinea pig because i'm the one who's good at math in the class lol. but the programming part? making an algorithm to do division the way russian peasants used to? it was very confusing. i got to a to-do list of things i wanted the program to do. but i have no idea how to translate that into programming. joel said he'd look at it with me. i'm so grateful he knows this stuff. because i'm so lost. i might as well be a goldfish in a forest for all i understand of python. my classmates are nice, too. i'm glad they're there, but i think i'm one of a couple people who aren't doing so well in getting things done. one had to withdraw from the class and did so once he left; i'm kinda sad he won't be in the class anymore. he's cool.
but the rest of my classmates are super nice and i was happy to share my snacks with them because programming without chocolate is not a thing i want to do lol.
once class was over i stopped at dairy queen for burgers and ice cream and came back to joel's and sat in for the remainder of our star wars game for the week, even though i didn't do much.
and now joel and i are in bed and i just want to sleep for a long time.
i do have to ask my classmate whose name eludes me if they'd be willing to sit with me and help me work through some programming stuff. i'll send them a message on discord tomorrow, i think, because they set up a server for the class and im so glad they did lol. much needed. i'm such a problem.
1 note
·
View note
Text
How to Write a Resume That Stands Out in 2025
A well-crafted resume is your ticket to landing job interviews. In 2025, the job market continues to evolve, and employers are looking for resumes that are not only professional but also optimized for digital screening tools. If you want to stand out among thousands of applicants, your resume needs to be strategic, engaging, and tailored to modern hiring practices. Here’s how to craft a resume that gets noticed in 2025.
1. Optimize for Applicant Tracking Systems (ATS)
Most companies now use Applicant Tracking Systems (ATS) to filter resumes before they even reach a hiring manager. To ensure your resume gets past these systems: Use keywords from the job description. Stick to a clean, simple format (avoid excessive graphics, tables, and columns). Save your file in PDF or .docx format for better compatibility.
Platforms like the ATSMantra Job Portal provide tools to check if your resume is ATS-friendly, helping you increase your chances of being shortlisted.
2. Start with a Strong Summary
Your resume should begin with a powerful professional summary instead of an outdated objective statement. This section should be:
Concise (3–4 sentences max).
Job-focused, highlighting your experience, skills, and what you bring to the table.
Customized to the role you’re applying for.
Example:🚀 Dynamic marketing specialist with 5+ years of experience in digital campaigns, content strategy, and brand management. Proven track record of driving customer engagement and increasing revenue through data-driven marketing initiatives.
3. Highlight Skills with a Modern Approach
Instead of just listing skills in a boring bullet format, integrate them into your achievements. Employers prefer to see how you applied your skills in real-world situations.
Hard Skills
SEO Optimization
Python Programming
Data Analytics
Soft Skills
Leadership & Team Collaboration
Strategic Problem-Solving
Strong Communication
💡 Pro Tip: Some job portals, including top job search platforms, allow you to showcase your skills through assessments or badges, making you a more attractive candidate.
4. Use Data-Backed Achievements
Rather than just listing responsibilities, highlight measurable achievements. Numbers help recruiters quickly gauge your impact.
🚀 Instead of:"Managed social media accounts and increased engagement."
Try:"Increased social media engagement by 45% in six months by developing a data-driven content strategy."
Tip: Use metrics like percentages, revenue growth, customer engagement, project timelines, or cost savings to add credibility to your experience.
5. Keep Your Resume Concise and Well-Formatted
Hiring managers spend an average of 6–10 seconds scanning a resume before deciding if they want to read further. Here’s how to make your resume easy to skim:
Keep it one page (for professionals with <10 years of experience) or two pages max for seasoned professionals.
Use clear headings, bullet points, and consistent fonts (Arial, Calibri, or Times New Roman work best).
Avoid long paragraphs—stick to concise, action-driven statements.
Do:"Led a team of 5 developers to complete a product launch 3 weeks ahead of schedule, resulting in a 20% increase in customer sign-ups."
Don’t:"I was responsible for managing a team of developers and ensuring our product was launched successfully before the deadline."
6. Include Relevant Keywords for Online Visibility
Many employers source candidates through online portals. To improve your resume’s visibility:
Use industry-specific keywords that match job descriptions.
Avoid generic buzzwords like "hardworking" or "team player" unless you back them up with real examples.
Add modern job titles (e.g., “Digital Marketing Strategist” instead of “Marketing Specialist”) to align with hiring trends.
Using a top job search platform that allows resume optimization will help you identify missing keywords and increase your chances of ranking higher in employer searches.
7. Leverage AI Tools and Resume Builders
In 2025, AI-powered tools have made resume writing easier than ever. Use platforms that provide: AI-based resume scoring.Grammar and readability checks.Suggestions for stronger action verbs.
If you’re applying through career opportunities with ATSMantra, consider using their resume optimization tools to ensure your resume aligns with industry standards.
8. Add a Portfolio or Online Presence
Many industries now expect candidates to showcase their work online. If applicable, include:
A LinkedIn profile with updated experiences and endorsements.
A personal website or portfolio (especially for designers, writers, and developers).
A GitHub link (for software engineers).
Tip: If you're applying for creative roles, some job opportunities worldwide require a portfolio submission, so always be prepared!
9. Tailor Your Resume for Every Application
A one-size-fits-all resume doesn’t work anymore. Employers want to see why you’re a great fit for THEIR specific role. Before submitting your resume: Adjust your skills and summary to match the job description. Highlight experience most relevant to that specific position. Use action verbs that align with the job’s responsibilities.
Using customized resumes increases your chances of landing interviews, making your job search more effective.
Final Thoughts: Stand Out and Get Hired!
In 2025, crafting a standout resume requires more than just listing your past jobs. It’s about presenting your skills, achievements, and experience in a strategic and modern way. By optimizing for ATS, using measurable results, and leveraging AI tools, you can boost your chances of getting noticed and securing interviews faster.
Whether you’re using the ATSMantra Job Portal or another top job search platform, applying these strategies will give you an edge over the competition. Get started today and make your resume work for you!
0 notes
Text
How to Build a Standout Resume in 2025

A good resume is the key to getting your dream job. Whether you are a fresher starting out or looking for a new opportunity, your resume should highlight your skills and strengths effectively. With the rise of startups in India and demand for roles like IT fresher jobs or MBA fresher jobs, you need a resume that grabs attention. Platforms like Salarite help connect job seekers with opportunities, but your resume is what sets you apart. Here’s how you can create a standout resume in 2025.
1. Know the Job You Want
Before writing your resume, research the job and company. Are you applying for jobs in startups or fresher jobs near me? Tailor your resume to match the role.
Tips:
Highlight the skills and experience the company is looking for.
Use keywords from the job description, like "IT jobs" or "startup company."
2. Pick the Right Format
Choose a resume format that makes your information easy to read.
Common Formats:
Chronological: Great for experienced professionals.
Functional: Focuses on skills, ideal for freshers.
Combination: Mix of both, suitable for most people.
3. Write a Strong Summary
Start your resume with a summary that introduces you.
Example: "Enthusiastic Computer Science graduate skilled in Python and data analysis. Looking for IT fresher jobs in a dynamic startup company to apply innovative solutions."
4. Show Your Skills
List both technical and soft skills relevant to the job.
Examples:
Technical: Programming, data analysis, cloud computing.
Soft: Communication, teamwork, problem-solving.
5. Add Experience or Projects
If you’re a fresher, include internships, college projects, or volunteer work. For startup jobs, focus on showing your ability to adapt and innovate.
Examples:
"Built a mobile app during college that improved task management."
"Interned at a tech startup, helping improve user engagement by 20%."
6. Highlight Education and Certifications
Include your degrees, coursework, and any certifications.
Example:
Bachelor of Technology in Computer Science, XYZ University (2025)
Certified in Digital Marketing (2024)
7. Use Numbers to Show Results
Whenever possible, use numbers to show what you’ve achieved.
Examples:
"Increased sales by 15% during a summer internship."
"Improved project delivery time by 20% using agile methods."
8. Use Keywords for Software Screening
Many companies use software to screen resumes. Include words like "fresher jobs," "IT jobs," or "jobs near me" from the job description.
9. Add Links to Your Portfolio
Include links to your LinkedIn profile or a portfolio if relevant.
Example: "Portfolio: www.myportfolio.com | LinkedIn: linkedin.com/in/myprofile"
10. Focus on Soft Skills
Startups often look for people who are flexible and good at solving problems. Mention these skills.
Examples:
"Adapted to fast-paced project requirements in a team environment."
"Organized events, improving participation by 30%."
11. Check for Mistakes
Make sure your resume has no spelling or grammar errors. Use tools like Grammarly or ask someone to review it.
12. Keep It Short and Clear
For freshers, a one-page resume is best. For experienced candidates, two pages are okay.
Conclusion
Creating a standout resume in 2025 means tailoring it to the job and showing your best skills. Whether you’re applying for jobs for freshers, IT jobs, or roles in a startup company, your resume should clearly show why you’re the right person for the job. Use these tips and platforms like Salarite to find the perfect opportunity and stand out to recruiters.
0 notes
Text
How to Use a Python Library in Java via Its API
Combining different programming languages in a single project can be very powerful. One useful combination is using Python libraries in a Java program. This lets you take advantage of Python’s many tools, like those for data analysis or machine learning, while still using Java’s strength in building large, reliable applications. This guide will show you how to use a Python library in Java through an API.

Why Combine Python and Java?
Python is known for being easy to use and having many libraries that can help with various tasks, like data processing or machine learning. On the other hand, Java is a popular choice for big projects because it’s fast and reliable. By combining the two, you can use Python’s great tools in a Java program, getting the best of both worlds.
One way to make Python and Java work together is by using an API. An API, or Application Programming Interface, is like a bridge that lets different software pieces talk to each other. In this case, the API lets your Java program use Python libraries.
Step 1: Choosing the Right Tools
To start, you need the right tools to connect Python and Java. Here are a few options:
Jython: Jython is a version of Python that runs on the Java platform. It allows you to use Python code directly in Java. However, it doesn’t support the latest Python versions, and it may not be as fast as other options.
Py4J: Py4J allows Java programs to run Python code and share data between the two languages. It’s a flexible and popular choice for this kind of integration.
Jep (Java Embedded Python): Jep embeds a Python interpreter in Java applications, allowing you to run Python code from Java. It’s designed to be fast, making it a good choice for performance-sensitive tasks.
Step 2: Setting Up Your Environment
We’ll focus on using Py4J to call a Python library from Java. Here’s how to set up your environment:
Install Python: First, make sure Python is installed on your computer. You can download it from the official Python website.
Install Py4J: Next, install Py4J by running this command in your terminal:

3. Set Up a Java Project: Create a new Java project using your preferred IDE, like IntelliJ IDEA or Eclipse. Add the Py4J library to your Java project. You can download it from the Py4J website or add it using a build tool like Maven or Gradle.
Step 3: Writing the Python Code
Let’s say you want to use a Python library called NumPy to calculate the square of a number. First, create a Python script that does this. Here’s an example:

Save this script as my_script.py in your working directory.
Step 4: Writing the Java Code
Now, write the Java code to call this Python script using Py4J. Here’s an example:
import py4j.GatewayServer;
public class PythonCaller {
public static void main(String[] args) {
GatewayServer gatewayServer = new GatewayServer();
gatewayServer.start();
System.out.println("Gateway Server Started");
try {
Process process = Runtime.getRuntime().exec("python my_script.py");
BufferedReader in = new BufferedReader(new InputStreamReader(process.getInputStream()));
String result;
while ((result = in.readLine()) != null) {
System.out.println(result);
}
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
This Java code starts a Py4J gateway server to connect with Python. It then runs the Python script using the Runtime.exec() method and prints the result.
Step 5: Running and Testing
After setting up your Python and Java code, you can run your Java program. Here’s what will happen:
The Java program starts the Py4J gateway server.
The Java program runs the Python script.
The result from the Python script is printed out by the Java program.
You can test this setup by trying different Python libraries, like pandas for data analysis or scikit-learn for machine learning, and see how they work with your Java program.
Step 6: Sharing Data Between Java and Python
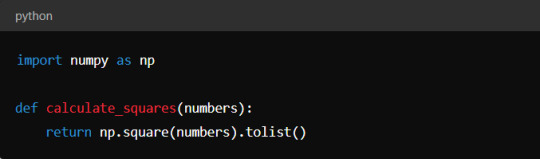
Often, you’ll want to pass data back and forth between Java and Python. Py4J makes this easy. For example, you can send a list of numbers from Java to Python, have Python square them using NumPy, and then return the squared numbers to Java.
Python Script (my_script.py):
Java Code:
import py4j.GatewayServer;
import py4j.Py4JNetworkException;
import java.util.Arrays;
import java.util.List;
public class PythonCaller {
public static void main(String[] args) {
GatewayServer gatewayServer = new GatewayServer(new PythonCaller());
gatewayServer.start();
try {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Object[] results = gatewayServer.getPythonServerEntryPoint(new Class[] {}).calculate_squares(numbers);
System.out.println("Squared numbers: " + Arrays.toString(results));
} catch (Py4JNetworkException e) {
e.printStackTrace();
}
}
}
Best Practices to Keep in Mind
When using Python in a Java program, there are a few things to remember:
Error Handling: Make sure your Java code can handle any errors that might come up when running Python code. This will help keep your Java program stable.
Performance: Running Python code from Java can slow things down, especially if you’re working with large amounts of data. Test your setup to make sure it’s fast enough for your needs.
Security: Be careful when running external scripts, especially if they use user input. Make sure inputs are safe and won’t cause security issues.
Documentation: Keep good notes on how your Python and Java code work together. This will make it easier to update or fix your code later on.
Conclusion
Using Python libraries in a Java program can make your projects much more powerful. By following these steps, you can set up a system where Java and Python work together smoothly. Whether you’re doing data analysis, machine learning, or any other task, combining Python and Java can help you get more done with your code.
#python training institute in course#python certifition course#python training course#best python courses#python programming course
0 notes
Text
Understanding Method Overloading and Overriding in Python: Python for Data Science
Summary: Method overloading and overriding in Python improve code flexibility and maintainability. Although Python doesn’t support traditional overloading, similar effects can be achieved using default and variable-length arguments. Overriding customises inherited methods, which is crucial for effective data science coding.

Introduction
Method overloading and overriding in Python are key concepts that enhance the functionality and flexibility of code. For data scientists, mastering these concepts is crucial for building efficient, reusable, and maintainable code. Understanding method overloading and overriding helps data scientists customise functions and classes, making their data analysis and machine learning models more robust.
In this article, you'll learn the differences between method overloading and overriding, how to implement them in Python, and their practical applications in Python for data science. This knowledge will empower you to write more effective and adaptable Python code.
What is Method Overloading in Python?
Method overloading is a feature in programming that allows multiple methods to have the same name but different parameters. It enhances code readability and reusability by enabling methods to perform different tasks based on the arguments passed.
This concept is particularly useful in data science for creating flexible and adaptable functions, such as those used in data manipulation or statistical calculations.
Implementation in Python
Unlike some other programming languages, Python does not support method overloading natively. In Python, defining multiple methods with the same name within a class will overwrite the previous definitions. However, Python's dynamic nature and support for default arguments, variable-length arguments, and keyword arguments allow for similar functionality.
To achieve method overloading, developers can use default arguments or variable-length arguments (*args and **kwargs). These techniques enable a single method to handle different numbers and types of arguments, simulating the effect of method overloading.
Examples
Here are some examples to illustrate method overloading in Python:
Using Default Arguments
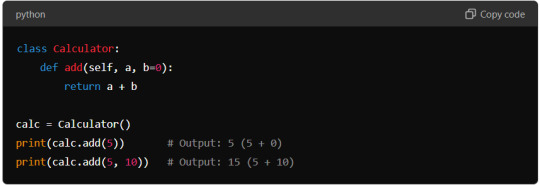
In this example, the add method can take either one or two arguments. If only one argument is provided, the method adds 0 to it by default.
2. Using Variable-Length Arguments
Here, the add method accepts a variable number of arguments using *args. This allows the method to handle any number of parameters, providing flexibility similar to method overloading.
Method overloading in Python, while not supported natively, can be effectively simulated using these techniques. This flexibility is valuable for creating versatile functions that can handle various input scenarios, making code more adaptable and easier to maintain.
What is Method Overriding in Python?
Method overriding is a fundamental concept in object-oriented programming (OOP) that allows a subclass to provide a specific implementation of a method that is already defined in its superclass.
This concept is crucial as it enables polymorphism, where different classes can implement methods in different ways while sharing the same method name. By overriding methods, developers can customise or extend the behavior of inherited methods without altering the original class.
Implementation in Python
In Python, method overriding occurs when a subclass defines a method with the same name and signature as a method in its superclass. When an instance of the subclass calls this method, the overridden version in the subclass executes, replacing the superclass's method.
This behavior demonstrates Python’s support for dynamic method dispatch, a key feature of polymorphism.
To override a method in Python, you simply define a method in the subclass with the same name as the one in the superclass. Python does not require any special syntax for overriding methods, making it straightforward to implement. Here’s an example:
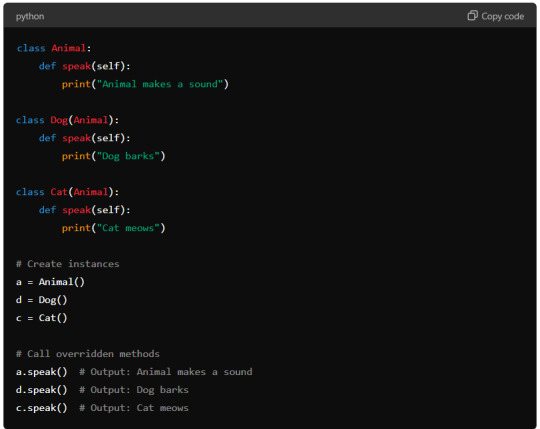
In this example, the speak method in the Dog and Cat classes overrides the speak method in the Animal class. When calling speak on an instance of Dog or Cat, the overridden methods in the respective subclasses execute, demonstrating how Python’s method overriding works in practice.
Practical Applications in Data Science
Understanding method overloading and overriding in Python has practical benefits in data science. These concepts play a critical role in simplifying and enhancing various data science tasks, from preprocessing data to evaluating models and customising algorithms.
Method Overloading in Data Science
Method overloading allows you to create multiple versions of a method, each with different parameters. While Python does not support method overloading in the traditional sense, you can achieve similar functionality using default arguments or variable-length arguments.
In data preprocessing, for instance, method overloading helps manage different types of data inputs. Suppose you are developing a data cleaning function that handles various formats—such as CSV, JSON, or XML.
By overloading methods with default arguments, you can design a single function that adapts to different data sources without needing separate implementations for each format. This approach enhances code readability and maintainability, as it centralises the preprocessing logic.
Another example is in model evaluation. You may need to evaluate models using different metrics depending on the specific needs of your analysis. Overloading methods that handle various evaluation metrics can streamline this process, allowing you to pass different metric parameters to a single evaluation function.
Method Overriding in Data Science
Method overriding is particularly valuable when you need to customise or extend existing functionalities. In data science, overriding methods becomes essential when working with frameworks or libraries that provide base classes with predefined methods.
For example, when using a machine learning library like scikit-learn, you might need to extend a base model class to create a custom model with additional features. By overriding methods in the base class, you can modify or extend the model’s behavior to fit your specific needs, such as implementing a custom training algorithm or adjusting hyperparameter tuning processes.
Additionally, method overriding is useful in feature engineering, where you might need to adapt base feature extraction classes to handle domain-specific features or preprocessing techniques. This customisation ensures that your data science workflows are flexible and tailored to the unique requirements of your projects.
Best Practices for Using Method Overloading and Overriding in Python
When working with method overloading and overriding in Python, following best practices ensures that your code remains clear, efficient, and robust. Understanding these practices helps you write maintainable code and avoid common pitfalls.
Coding Standards
To keep your code clean and maintainable, follow these guidelines:
Use Descriptive Method Names: Even though Python doesn’t support traditional method overloading, using descriptive names or default arguments can improve readability. For example, instead of creating multiple process_data methods, use process_data with different parameters.
Consistent Parameter Usage: When overriding methods, ensure that the parameters and their meanings are consistent with the base class. This consistency prevents confusion and makes it easier to understand the code.
Document Your Code: Always document your methods with clear docstrings. Explain what each method does, its parameters, and its return values. This practice enhances code readability and helps others understand the purpose of method overloads or overrides.
Performance Considerations
Performance may be impacted by method overloading and overriding in the following ways:
Method Resolution: Python’s method resolution order (MRO) can impact performance, especially in complex class hierarchies. Ensure that your method overrides are necessary and avoid deep inheritance trees when possible.
Dynamic Typing: Python's dynamic typing allows for flexible method implementations, but this can lead to runtime performance costs. Minimise the use of complex logic within overloaded or overridden methods to avoid performance hits.
Error Handling
Proper error handling prevents issues when dealing with method overloading and overriding:
Use Try-Except Blocks: Enclose critical method calls within try-except blocks to catch and handle exceptions gracefully. This approach helps maintain code stability even when unexpected errors occur.
Validate Parameters: Implement parameter validation in overridden methods to ensure that the inputs are as expected. This validation helps prevent runtime errors and improves method reliability.
By adhering to these best practices, you can effectively manage method overloading and overriding in Python, resulting in more maintainable and efficient code.
Frequently Asked Questions
What is method overloading in Python?
Method overloading in Python allows multiple methods to have the same name but different parameters. Although Python doesn't support traditional overloading, similar functionality can be achieved using default arguments and variable-length arguments.
How does method overriding differ from overloading in Python?
Method overriding occurs when a subclass provides a specific implementation of a method defined in its superclass. Unlike overloading, which handles different arguments, overriding customises or extends existing methods, enabling polymorphism.
Why are method overloading and overriding important in Python for data science?
Method overloading and overriding enhance code flexibility and reusability. In data science, they help create adaptable functions for data preprocessing and model evaluation, improving code maintainability and customisation.
Conclusion
Understanding method overloading and overriding in Python is vital for data scientists aiming to write flexible and maintainable code. While Python lacks native support for method overloading, techniques like default arguments and variable-length arguments offer similar functionality.
Method overriding allows customisation of inherited methods, promoting code reusability. Mastering these concepts will enhance your data science projects, making your code more robust and adaptable to various tasks.
#Method Overloading and Overriding in Python#Method Overloading#Method Overriding#Python#Python Programming#data science
0 notes
Text
Code Embedding: A Comprehensive Guide
New Post has been published on https://thedigitalinsider.com/code-embedding-a-comprehensive-guide/
Code Embedding: A Comprehensive Guide
Code embeddings are a transformative way to represent code snippets as dense vectors in a continuous space. These embeddings capture the semantic and functional relationships between code snippets, enabling powerful applications in AI-assisted programming. Similar to word embeddings in natural language processing (NLP), code embeddings position similar code snippets close together in the vector space, allowing machines to understand and manipulate code more effectively.
What are Code Embeddings?
Code embeddings convert complex code structures into numerical vectors that capture the meaning and functionality of the code. Unlike traditional methods that treat code as sequences of characters, embeddings capture the semantic relationships between parts of the code. This is crucial for various AI-driven software engineering tasks, such as code search, completion, bug detection, and more.
For example, consider these two Python functions:
def add_numbers(a, b): return a + b
def sum_two_values(x, y): result = x + y return result
While these functions look different syntactically, they perform the same operation. A good code embedding would represent these two functions with similar vectors, capturing their functional similarity despite their textual differences.
Vector Embedding
How are Code Embeddings Created?
There are different techniques for creating code embeddings. One common approach involves using neural networks to learn these representations from a large dataset of code. The network analyzes the code structure, including tokens (keywords, identifiers), syntax (how the code is structured), and potentially comments to learn the relationships between different code snippets.
Let’s break down the process:
Code as a Sequence: First, code snippets are treated as sequences of tokens (variables, keywords, operators).
Neural Network Training: A neural network processes these sequences and learns to map them to fixed-size vector representations. The network considers factors like syntax, semantics, and relationships between code elements.
Capturing Similarities: The training aims to position similar code snippets (with similar functionality) close together in the vector space. This allows for tasks like finding similar code or comparing functionality.
Here’s a simplified Python example of how you might preprocess code for embedding:
import ast def tokenize_code(code_string): tree = ast.parse(code_string) tokens = [] for node in ast.walk(tree): if isinstance(node, ast.Name): tokens.append(node.id) elif isinstance(node, ast.Str): tokens.append('STRING') elif isinstance(node, ast.Num): tokens.append('NUMBER') # Add more node types as needed return tokens # Example usage code = """ def greet(name): print("Hello, " + name + "!") """ tokens = tokenize_code(code) print(tokens) # Output: ['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']
This tokenized representation can then be fed into a neural network for embedding.
Existing Approaches to Code Embedding
Existing methods for code embedding can be classified into three main categories:
Token-Based Methods
Token-based methods treat code as a sequence of lexical tokens. Techniques like Term Frequency-Inverse Document Frequency (TF-IDF) and deep learning models like CodeBERT fall into this category.
Tree-Based Methods
Tree-based methods parse code into abstract syntax trees (ASTs) or other tree structures, capturing the syntactic and semantic rules of the code. Examples include tree-based neural networks and models like code2vec and ASTNN.
Graph-Based Methods
Graph-based methods construct graphs from code, such as control flow graphs (CFGs) and data flow graphs (DFGs), to represent the dynamic behavior and dependencies of the code. GraphCodeBERT is a notable example.
TransformCode: A Framework for Code Embedding
TransformCode: Unsupervised learning of code embedding
TransformCode is a framework that addresses the limitations of existing methods by learning code embeddings in a contrastive learning manner. It is encoder-agnostic and language-agnostic, meaning it can leverage any encoder model and handle any programming language.
The diagram above illustrates the framework of TransformCode for unsupervised learning of code embedding using contrastive learning. It consists of two main phases: Before Training and Contrastive Learning for Training. Here’s a detailed explanation of each component:
Before Training
1. Data Preprocessing:
Dataset: The initial input is a dataset containing code snippets.
Normalized Code: The code snippets undergo normalization to remove comments and rename variables to a standard format. This helps in reducing the influence of variable naming on the learning process and improves the generalizability of the model.
Code Transformation: The normalized code is then transformed using various syntactic and semantic transformations to generate positive samples. These transformations ensure that the semantic meaning of the code remains unchanged, providing diverse and robust samples for contrastive learning.
2. Tokenization:
Train Tokenizer: A tokenizer is trained on the code dataset to convert code text into embeddings. This involves breaking down the code into smaller units, such as tokens, that can be processed by the model.
Embedding Dataset: The trained tokenizer is used to convert the entire code dataset into embeddings, which serve as the input for the contrastive learning phase.
Contrastive Learning for Training
3. Training Process:
Train Sample: A sample from the training dataset is selected as the query code representation.
Positive Sample: The corresponding positive sample is the transformed version of the query code, obtained during the data preprocessing phase.
Negative Samples in Batch: Negative samples are all other code samples in the current mini-batch that are different from the positive sample.
4. Encoder and Momentum Encoder:
Transformer Encoder with Relative Position and MLP Projection Head: Both the query and positive samples are fed into a Transformer encoder. The encoder incorporates relative position encoding to capture the syntactic structure and relationships between tokens in the code. An MLP (Multi-Layer Perceptron) projection head is used to map the encoded representations to a lower-dimensional space where the contrastive learning objective is applied.
Momentum Encoder: A momentum encoder is also used, which is updated by a moving average of the query encoder’s parameters. This helps maintain the consistency and diversity of the representations, preventing the collapse of the contrastive loss. The negative samples are encoded using this momentum encoder and enqueued for the contrastive learning process.
5. Contrastive Learning Objective:
Compute InfoNCE Loss (Similarity): The InfoNCE (Noise Contrastive Estimation) loss is computed to maximize the similarity between the query and positive samples while minimizing the similarity between the query and negative samples. This objective ensures that the learned embeddings are discriminative and robust, capturing the semantic similarity of the code snippets.
The entire framework leverages the strengths of contrastive learning to learn meaningful and robust code embeddings from unlabeled data. The use of AST transformations and a momentum encoder further enhances the quality and efficiency of the learned representations, making TransformCode a powerful tool for various software engineering tasks.
Key Features of TransformCode
Flexibility and Adaptability: Can be extended to various downstream tasks requiring code representation.
Efficiency and Scalability: Does not require a large model or extensive training data, supporting any programming language.
Unsupervised and Supervised Learning: Can be applied to both learning scenarios by incorporating task-specific labels or objectives.
Adjustable Parameters: The number of encoder parameters can be adjusted based on available computing resources.
TransformCode introduces A data-augmentation technique called AST transformation, applying syntactic and semantic transformations to the original code snippets. This generates diverse and robust samples for contrastive learning.
Applications of Code Embeddings
Code embeddings have revolutionized various aspects of software engineering by transforming code from a textual format to a numerical representation usable by machine learning models. Here are some key applications:
Improved Code Search
Traditionally, code search relied on keyword matching, which often led to irrelevant results. Code embeddings enable semantic search, where code snippets are ranked based on their similarity in functionality, even if they use different keywords. This significantly improves the accuracy and efficiency of finding relevant code within large codebases.
Smarter Code Completion
Code completion tools suggest relevant code snippets based on the current context. By leveraging code embeddings, these tools can provide more accurate and helpful suggestions by understanding the semantic meaning of the code being written. This translates to faster and more productive coding experiences.
Automated Code Correction and Bug Detection
Code embeddings can be used to identify patterns that often indicate bugs or inefficiencies in code. By analyzing the similarity between code snippets and known bug patterns, these systems can automatically suggest fixes or highlight areas that might require further inspection.
Enhanced Code Summarization and Documentation Generation
Large codebases often lack proper documentation, making it difficult for new developers to understand their workings. Code embeddings can create concise summaries that capture the essence of the code’s functionality. This not only improves code maintainability but also facilitates knowledge transfer within development teams.
Improved Code Reviews
Code reviews are crucial for maintaining code quality. Code embeddings can assist reviewers by highlighting potential issues and suggesting improvements. Additionally, they can facilitate comparisons between different code versions, making the review process more efficient.
Cross-Lingual Code Processing
The world of software development is not limited to a single programming language. Code embeddings hold promise for facilitating cross-lingual code processing tasks. By capturing the semantic relationships between code written in different languages, these techniques could enable tasks like code search and analysis across programming languages.
Choosing the Right Code Embedding Model
There’s no one-size-fits-all solution for choosing a code embedding model. The best model depends on various factors, including the specific objective, the programming language, and available resources.
Key Considerations:
Specific Objective: For code completion, a model adept at local semantics (like word2vec-based) might be sufficient. For code search requiring understanding broader context, graph-based models might be better.
Programming Language: Some models are tailored for specific languages (e.g., Java, Python), while others are more general-purpose.
Available Resources: Consider the computational power required to train and use the model. Complex models might not be feasible for resource-constrained environments.
Additional Tips:
Experimentation is Key: Don’t be afraid to experiment with a few different models to see which one performs best for your specific dataset and use case.
Stay Updated: The field of code embeddings is constantly evolving. Keep an eye on new models and research to ensure you’re using the latest advancements.
Community Resources: Utilize online communities and forums dedicated to code embeddings. These can be valuable sources of information and insights from other developers.
The Future of Code Embeddings
As research in this area continues, code embeddings are poised to play an increasingly central role in software engineering. By enabling machines to understand code on a deeper level, they can revolutionize the way we develop, maintain, and interact with software.
References and Further Reading
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
GraphCodeBERT: Pre-trained Code Representation Learning with Data Flow
InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees
Transformers: Attention Is All You Need
Contrastive Learning for Unsupervised Code Embedding
#Abstract Syntax Tree#ai#Analysis#applications#approach#Artificial Intelligence#attention#Behavior#bug#bugs#Capture#code#Code Embedding#Code embeddings#Code Review#Code Search#Code2vec#CodeBERT#coding#Community#comprehensive#computing#continuous#contrastive learning#data#Deep Learning#detection#developers#development#diversity
0 notes